
David Rogers writes about his work investigating mysterious symbols discovered in the front of a prayer book by Dr Emilie Murphy.
In September 2021, I was doomscrolling twitter and spotted Dr Emilie Murphy’s tweet asking if anyone recognised this text. I was immediately interested and contacted her to discuss further. Emilie explained that the text had been discovered on the inside of a 1624 copy of the ‘Whole Booke of Psalmes’, bound with a 1624 copy of the Book of Common Prayer and a 1623 New Testament – all in English. There were no other annotations to the text and it was discovered on one of the boards of the book.

When I originally saw the document, I thought it would be a simple substitution cipher of some sort and that it might be a bit hard to look at because of the handwriting. I quickly realised that it wasn’t and that it was probably a 1600s shorthand. I focused in on Shelton’s shorthand (also known as Tachygraphy), as I could find some characters that looked very similar.
Thomas Shelton invented his shorthand in the mid-1600s, developing and evolving earlier methods. His version became very popular and was used for documenting oral proceedings from Parliament through to legal cases. There are a number of examples of earlier types that I’ll talk about in more detail in a future blog, including a couple of histories which are available to read online, one of which was written in 1736. One example is the Stenographer Theophilus Metcalfe’s shorthand, which was used to record the proceedings of the Salem witch trials. Shelton’s shorthand was also used Sir Isaac Newton and famously by Samuel Pepys (you’ll often hear people say that he wrote his diary in code which I guess it is, but it was because he also used this on a daily basis in his work). In many cases, the shorthand representations in documents represent an almost word-for-word recording of what was said in a room.
Having looked at some examples, I was able to get a copy of The Augustan Reprint Society publication numbers 145-146 (1970) which contains both ‘A Tutor to Tachygraphy, or, Short-Writing’ (1642) and ‘Tachygraphy’ (1647) which have been very instructive in terms of how Tachygraphy works and how to read it. In short it is very complicated, but once you understand it’s logic and have memorised the techniques, it becomes more straightforward.
There are not many examples of shorthand real-world text online, but I found these copies of the Lord’s Prayer and The Creed, written in Shelton’s shorthand as part of a larger page (seemingly signed by Shelton himself), which were very useful as practice for understanding the application of the method and to decipher, already knowing the plaintext. As an aside, they are contained within the Miscellany of Henry Oxinden, an interesting collection of writings in itself and held in the Folger Library in Washington DC.

In the example above you can pick out all the words easily and then match them to Shelton’s tutor guide book. The above is very clearly written and you can follow the words easily because they are well separated. The Lord’s Prayer starts with ‘Our Father, who art in Heaven’ and you can match that:

I’ll come back to this later on, but in short this also helped me to at least move a bit closer to believing that the document I was looking at was written in Shelton’s shorthand.
Below is an example from Samuel Pepys’ diary – without going into too much detail, the reprint of the ‘Tutor to Tachygraphy’ book I have was actually originally from Pepys’ own collection which is now stored at Cambridge University in the Pepys library (shelfmark PL 402(11)).
You can see that Pepys writes his diary in a very orderly fashion. He also used some words in long-form, which was probably easier for him than trying to work out the construction of an unusual word which might be difficult to read later. In essence, Pepys diary would have been much easier to decipher than what we have in our document. You can see a good YouTube video explanation here by Guy de la Bédoyère, who is an expert in Shelton’s shorthand.
My Approach
Once I had pretty much established that this was Shelton’s shorthand, I wanted to have a go at picking out symbols that I could recognise. Up until now I’ve been pretty casual at attacking it, rather than going for a fully methodical run-through of each and every character (partly because I was not sure that it really was what I thought it was).
I should add at this point that this is really a background activity for me that I come back to from time-to-time, I have been generally trying to match symbols and also to learn / remember Shelton’s shorthand. When I’m travelling and I know I’ll have a little free time (which if you know me is not that often!), I will take this with me. My folder with my book and notes has been travelling round the world with me for a couple of years. I’m typing this on an overnight flight back from the hacking conference DEF CON in Las Vegas as I can’t sleep.
Anyway, what I’ve found is that each time I come back, it takes about an hour or so to get back into the mental rhythm of looking at it and re-engaging with the shorthand. I’ve also taken to writing some notes from time-to-time in shorthand just so that I can get used to using and reading it. The more I spend time looking at the document, the more things I observe. For example, you can see the points at where the author starts to run out of ink and then starts using new ink (see below). This really made me feel a connection to the person writing this – I can imagine them trying to remember what the person is saying while dipping into the ink!
Working hypothesis
My presumptions so far have been that the text is in English, that it is likely to be a sermon or prayer (being written into the inside cover of a prayer book), perhaps annotated by someone listening rather than written to deliver, because the handwriting appears to be rushed rather than methodically written (as I said above in the Pepys diary example, it is very well laid out and simple to read).
Picking out individual words
The Shelton books inside the reprint have some quite complicated and archaic ways of explaining how you use ‘short writing’ and I found that until I got a better understanding of the whole thing, the look-up tables were far more useful to me. As I got greater confidence, the explanations made a heck of a lot more sense and I might at some future point do a re-write of those for others who are looking at these types of texts.
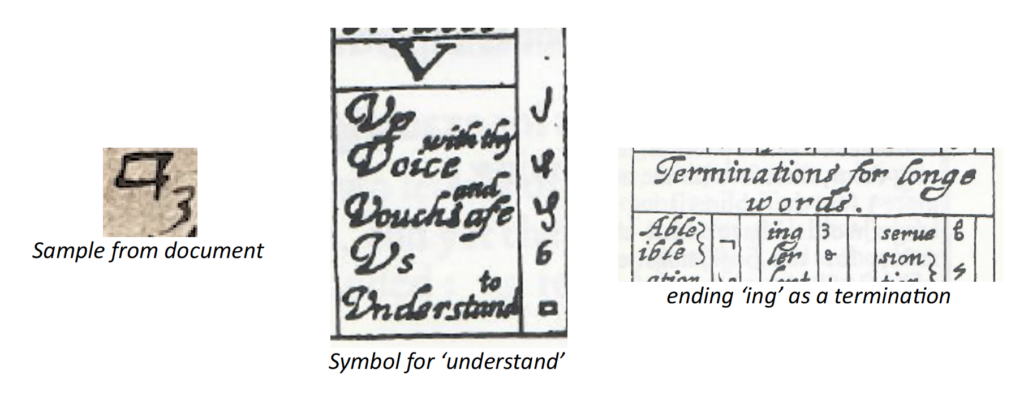
I have included this example as it is one of the clearer words in the document that matches with Shelton’s book on shorthand. The left-hand side shows what we have in the document and the right-hand side, the book – the symbol for ‘understand’ and then the ending ‘ing’. A lot of these words can be broken down and built up from scratch, however there are a lot of reserved words and characters, a lot that look like each other and some that are repeated. That’s also assuming that the thing is the same version of shorthand. There were many earlier versions of shorthand and variants, including in other languages and countries. To explain this a bit further I’ll use another example.
Father
As we saw earlier in the Lord’s Prayer and from my Shelton reference book, we already know the symbol(s) for the word father.

To briefly explain how this is formed, there are two parts, the first part of the word is the symbol フ, representing F and ![]() symbolises the ending ‘ther’.
symbolises the ending ‘ther’.
So how do we get to Father? Well the way that vowels are handled in words is that they are denoted by positions around the character, in a sort of imaginary semi-circle – a,e,i,o,u. So in our example above, the second part is positioned at the top middle of the character, meaning ‘a’. You have to look at these as phonetic rather than direct spellings, so reading the word out can help. The ending is one of those reserved characters and this is listed in Shelton’s list of word endings.
In our previous example of the word for understanding, the ending is also in the list ‘ing’, which is this symbol 3 to the right of the first part of the word. You can start to recognise these words more easily as you remember the rules and the dictionary of characters.
Here’re some examples of what I think are the word ‘Father’ in our text. You can see that because of the flow of the writing, the text and position isn’t 100% clear:

In, By, Give, God, Your
There are quite a few characters that are extremely similar, which can create real problems. They might become more obviously wrong later on and for now when I’m looking at these, I’m just handling them by also adding the other possible alternate. Some good illustrations are as follows.
In the Creed from the Lord’s Prayer and Creed image above, you can see two L-shaped characters that look almost the same, but they’re not. One means ‘by’ and the other means ‘in.
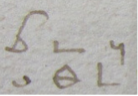
Here are a couple of examples from our own document:

The same with your and give and the word for God, which either share characters or look similar to a y. This happens in a number of places and can be really compounded when the writing is not clear (as is the case in our document).
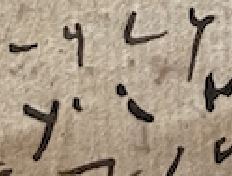
I’ll give some other explanations of words in future blogs. The final thing to note is that there are also some characters that look a bit strange and out of place in Shelton’s shorthand. I’ll also discuss this in further in the future as I begin to understand them a bit more.
What Next?
I think that my next plan is to make a full-frontal attack on the text. I’ve cut out the lines so I can more easily annotate them and I will probably formalise this by numbering each character. There is a complicating factor to this which is that some words are made up of multiple characters so this may really screw up any system that I employ, although I can think of some ways of managing this.
I could also try to do some character / word frequency analysis – I may do this after I’ve done my first complete sweep of the document. This may help to confirm that the document is in English as we simply can’t say 100% that it is.
My real aim is to be able to find a solidly coherent sentence of text, part of me wants this to be something obvious like a bible passage, but part of me wants it to be a sermon – to be able to be the first person to ‘hear’ a voice from nearly 500 years ago, with the words that came directly from their mouth.
A Note on Machine-Learning and Automation
When I’ve mentioned this document to people or when they’ve seen me looking at it, my hacker and engineer friends almost always ask me why I haven’t used machine-learning to help me or to train AI. There are a few reasons for this.
- I still don’t fully know (I’m maybe at 70%?) what we’re dealing with (more on this in future blogs).
- The writing in the document I have is not very clear so the ciphertext is not great material.
- I don’t have a lot of training data – at least not personally. If I could get copies of ciphertext where there was known plaintext, I might start to do this. An obvious starting point would be Cambridge where we know that there are documents from Pepys and Newton, but there are limited texts available on the internet.
- Re-use of or similar characters in the shorthand means that text context is more easily worked out a human – maybe the computer can just provide options from later triaging.
- Effort! In my basic weighing up of the situation, I’d probably have to spend a lot of time on the software development side which might be better used just doing it manually (at least this time). If I crack it, then I think I might be more enthused to start to write a tool to automate the process.
- The number of rules and quirks of these shorthand systems are quite complex, it is not simple pattern matching using Optical Character Recognition (OCR). I could probably write an initial tool that purely did that if I seeded it with an initial dictionary. That would then leave me with unusual words which I could attempt manually and either – add to the dictionary or develop an algorithm based on the rules which are outlined in Shelton’s books. I could reasonably easily then extend that to earlier versions of shorthand so that the system could identify which variant of shorthand we are dealing with (or suggest candidates).
I don’t know anyone who is working on anything like this currently (please do contact me if you are!), however I did find a paper from 2020 from researchers at Mapua University in Manila on deciphering Gregg shorthand (a modern version), which claimed a validation accuracy of 91%. A lot of work in academia is focused on using machine learning for different ancient languages. A paper published in 2023 by researchers from Google DeepMind and three different universities provides a survey of the various activities and tools being used in that space.
To be continued…